
15 Essential Practices Of DevOps
DevOps is a coined noun used to describe an evolution of existing IT best practices from ITIL®, Lean and Agile into a development and operations approach that supports automation and continuous delivery. DevOps also encourages a culture of collaboration and learning to help IT deliver business value better, faster and cheaper than ever before.

This post aims to explain 15 practices that are essential to the success of DevOps in any organisation.
1. Voice Of The Customer
Utility represents functional requirements. It describes those requirements of a service which are “fit for purpose” – does the service do what it is supposed to do? Is the performance of the service supported? Are there constraints present that will inhibit its functioning? The utility is the functionality of the service to meet a specific need.
Warranty represents non-functional requirements. It describes those requirements of a service which are “fit for use” – is the service actually delivered? Warranty means that the service is available and works when the customer needs it, with appropriate capacity, continuously and securely. The customer defines what value is, expressed in the context of a service or product!
Value changes over time with changing expectations. Therefore, it is critical to determine what is important to the customer with the changing expectations. Voice Of The Customer (VOC) is how Lean proposes understanding the end-to-end customer experience because ultimately the customer is the one who defines what value is.
Critical To Quality (CTQ) items are must-haves. According to the principles of Lean, it is the Critical To Quality value items that should be prioritized and focused on. If you aren’t delivering those, then you aren’t really delivering value.
2. Business Relationship Management
Business Relationship Management (BRM) seeks to establish and maintain the relationship between IT and internal business stakeholders, identify business value and ensure that IT understands and is able to deliver it. Business Relationship Manager is the person who really makes the BRM process effective by acting as a liaison between IT and internal business partners and stakeholders.
The role of the Business Relationship Manager is generally full-time as it is critical to maintaining the necessary relationships and ensuring that the services provided by IT are fit for purpose and deliver the necessary business value. This role is sometimes seen as creating silos because it is perceived that they enable the business and IT to avoid communication. Nothing could be further from the truth. The BRM can and should be a role that enables collaboration by acting less as a middleman and more as a facilitator, making introductions and ensuring that both sides understand each other.
3. Value Stream Mapping
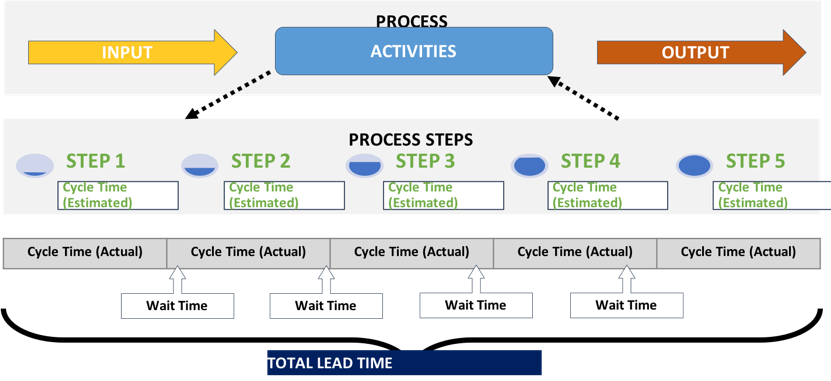
A Process is a structured set of activities designed to accomplish a specific objective. It takes one or more defined inputs and turns them into defined outputs. The Value Stream provides a holistic view of IT as delivering end-to-end business value. Understanding not only your own place within the value stream but the value stream as a whole is essential for leadership and governance.
- Cycle Time is the time spent actually creating products or services.
- Process Time is the total time spent actually creating products or services.
- Wait Time is the time spent waiting for next steps to begin.
- Lead Time is the time between input and output – the Process Time and Wait Time totalled together.
One of the key principles of Lean is to map the value stream – mapping the metrics against the steps in the process and using the data to focus in on particular problem areas or determine where the waste is and why it is happening, so that you can then prioritize effectively and find those areas where a quick win is possible.
4. Lean Process Optimisation
Lean IT is an improvement approach uniquely focused on pursuing the delivering of value to customers with the least amount of effort. As with Lean applied to other areas of business, Lean IT is not only concerned with delivering as much value as possible for customers. It is also focused on ensuring that the waste that often masks much of the customer value is removed. Hereby, value to customers is increased in two ways: by reducing the proportion of wasteful activities to value-adding activities and increasing the amount of value-related activities.
Waste within IT includes the traditional TIMWOOD waste categories:
- Transportation
- Inventory
- Motion
- Waiting Time
- Over-processing
- Overproduction
- Defects & Rework
Within IT, there is a very important additional waste: Talent. This is when the abilities of the people in the IT organisation are not used to their full extent.
Next, to traditional waste (or Muda), there are other two categories of loss: Variability (Mura) and Overburden (Muri).
Mura (variability) occurs when incoming work is not matched by the right number of people with the correct skills, thus leading to a wide range of possible outcome qualities. Variability is all about fluctuation, in cost, quality or throughput times.
Muri (overburden) is caused by fixed service timeframes, release windows and other such time constraints. Large inventories and a batch processing mechanism cause overburden and inflexibility, reducing the ability of processes to flow. In removing waste from an IT organization, it is vital for management to stimulate a review of Muri before tackling Mura, followed by Muda.
Further, in removing waste, Value-Add work should be optimized. It is the only work that the customer actually experiences and sees as value and is willing to pay for. Necessary NonValue-Add work should be minimized. This is work that is not a value-add, but that must be done. Non-Value-Add work should be removed.
5. Knowledge Management
Knowledge Management is the practice of embedding and making accessible the essential knowledge that is required to support a DevOps environment and ensure stable, effective services.
The DIKW Model helps us to understand the difference between a lack of data or information and a lack of knowledge or wisdom. By addressing this gap, the technical debt can also be reduced.
- Data is objective facts, observations, signs or symbols. It has no context or meaning and is not usable until the context is applied.
- Information is organized or structured data which has been given a context or purpose.
- Knowledge is information framed by individual experiences, values, insight or intuition.
- Wisdom requires higher level contexts and relational thinking.
Knowledge Management also enables the sharing of data, information and knowledge between Development and Operations, thereby facilitating better communication, collaboration and integration between Dev and Ops.
6. Visual Management
Visual Management is a tool used to make the control and management of an organization as simple as possible. The practice involves using visual controls in plain sight rather than text-based ones, where it is easier to interpret, remember and keep at the forefront of one’s mind.
Visual Management aims to achieve two objectives. Firstly, to increase the efficiency and effectiveness of a process and a value stream by making the steps visible. Secondly, visual management makes problems, abnormalities, or deviations from standards visible to everyone. When these deviations are visible and apparent to all, corrective action can be taken to immediately correct these problems.
7. Agile Project Management & Scrum
Traditionally, IT has used what is known as a Waterfall Project Management approach, which assumes that the specifications of the project are correct from the start. The scope is defined at the outset of the project and everything then “falls along” from there.
This project management style is also called predictive because it means that the final result must be known, and planning and design must be complete and correct before the next stage can begin. The code is integrated only after a build is fully complete. This approach values planning and strict management of timelines and schedules to reach the known end, the production-ready version.
On the other hand, Agile Project Management is an adaptive approach. This implies that requirements are expected to change and evolve as the project advances. It uses continual iterations to adapt and incorporate these changes.
Agile Project Management redefines scope after each iteration is complete. Scrum calls these iterations Sprints. By redefining the scope after each iteration, feedback and quality are built in to ensure that the customer is happy after each iteration, creating less waste and encouraging experimentation because we are able to fail fast and adapt quickly to change course.
Scrum is a subset of Agile. It is an adaptable process framework within which various processes, tools and techniques can be applied. It promotes the development of products in an iterative way that results in more frequent releases with the highest quality outcomes possible.
8. Shift Left Testing
Shift Left ensures that quality is built in earlier in the development process so that issues are detected earlier and can be resolved, and defects or errors do not impact production.
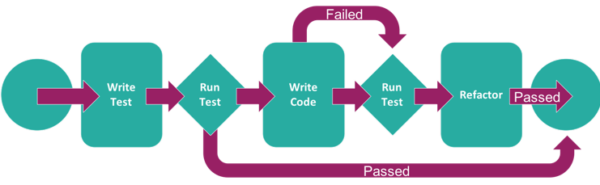
Test Driven Development (TDD) is the practice of preparing test scenarios before a program is written so that the goal for the programmer is to create the simplest possible program, just to pass the test.
This is desirable in DevOps and Agile environments since time is not wasted creating something perfect, while all that is needed is a good enough solution to do the job.
9. Change Management
Change Management is an ITIL process that controls the lifecycle of all changes, enabling beneficial changes to be made with minimum disruption to IT services. Change Management optimizes overall business risk.
Over time, the process and practices of Change Management allow for frequent, lower risk changes that follow a common procedure to be categorized as Standard Changes. Standard Changes can be processed and approved faster and improve the speed of delivery of change – one of the goals of DevOps.
10. Configuration Management
Configuration Management is an ITIL process that is crucial for DevOps because it is essential for automation. This process is about maintaining knowledge of the current state of every component in the infrastructure.
In a DevOps environment, Configuration Management encompasses the practices and tooling that automate the delivery and operation of infrastructure. Tools are used to:
- Model infrastructure;
- Continually enforce desired configurations;
- Remediate unexpected changes or “configuration drift”, differences over time between primary and secondary infrastructure configurations.
Automated Configuration Management is achieved in DevOps by treating Infrastructure As Code (IAC) that can be managed with the same tools and processes that developers use, such as version control, code review, automated testing and small deployments. This increases faster and more frequent changes and releases.
11. Release & Deployment Management
Release & Deployment Management provides guidance related to planning, scheduling and controlling releases as they transition from the development environment into production. The practices of Release & Deployment Management support DevOps.
Automate Configuration Management with IAC
Configuration Management that is automated and utilizes IAC supports Release Management process helps increase reliability and reduce error by automating software installation and configuration. It makes the release process more repeatable because scripts can be run repeatedly in both testing and production environments while maintaining version control.
Implement Zero-Downtime Deployment
Implementing zero-downtime deployments means finding ways to release software without affecting end-users. This is critical when servers are rebuilt regularly, which could lead to unacceptable levels of downtime.
Blue-Green Deployment
Blue-Green Deployment means setting up two identical production servers and directing all the user traffic going to only one of the server sets – an “Active” environment that is in production. This results in a “Passive” environment that is only used in development, and one that users cannot see or use.
With Blue-Green Deployment, changes can be deployed to the servers that are not being used, destroying and rebuilding the servers as needed, and nobody will be affected if it goes wrong. IT is no longer limited to deploying outside of normal hours to minimize the impact of downtime or having to worry about the impact of the change on end-users. When the passive environment is working as required, user traffic can be redirected to the new set of servers. Those servers become the new active environment, and the previously active environment can now be used as a passive one to begin the process again.
12. Incident Management
Incident Management is an ITIL process that restores normal service operation as quickly as possible in the event of an incident. It minimizes the adverse impact on business operations. It ensures that the best possible levels of service quality and availability are maintained.
When the Incident Management process is in place, it allows for faster resolution of incidents and quicker restoration of normal operation of services, resulting in better service availability.
13. Problem Management & Kaizen
Problem Management is an ITIL process which works to prioritize, identify and, if possible, resolve the root cause of one or more incidents in order to eliminate them or minimize their impact.
The more accountable the Development Team is made when something breaks, the less likely they will be to break it to begin with. It decreases a silo mentality and encourages collaboration. And, being involved with Incidents and Problems also encourages the experimentation and learning that are central to the Third Way.
Kaizen is a structured approach for solving problems around improving flow and processes incrementally, with an attitude or mindset that encourages everyone at every level of an organization to look for small ideas which, if possible, can be implemented easily and quickly. Kaizen should be part of the daily culture of an organization.
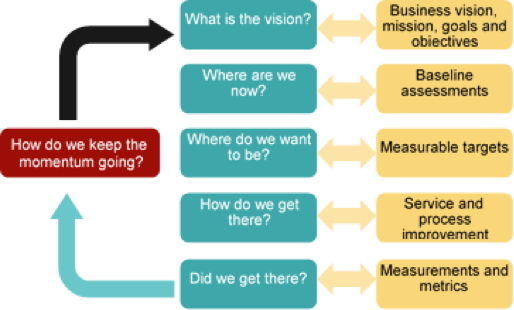
14. Continual Service Improvement
Continual Service Improvement is essential as a solution to the business and IT value delivery problems. It is a way to keep pace with the value the business demands and the pace with which competition is now emerging and the world is changing. It demands not just that organizations continually improve, but that they measure against that improvement and approach that improvement in a strategic way that focuses their attention on those constraints and areas where it will have the most impact.
The CSI Approach helps to align IT Services to the business needs by providing a structured approach to continual improvement, The Third Way.
15. Antifragility
Disaster Recovery is the means to respond to worst-case scenarios and protect critical systems from incidents and disruption.
Resilience is the means to respond to, but also resist, incidents and disruptions of all kinds.
Antifragility is the means to not only respond to and resist incidents and disruptions of all kinds, but to use them as an opportunity for learning and adaptation. An example of Antifragility is Chaos Engineering.
Chaos Engineering is an entire discipline that is all about achieving antifragility and ensuring stable performance even in the face of emergencies or unplanned incidents and outages. For example, in 2011, Netflix rolled out “Chaos Monkey,” a software that simulates failure by randomly shutting down production servers. Chaos Monkey deliberately damaged their own production environment in order to determine if the software could survive it! This evolved into a collection of cloud testing tools to simulate other potential failures that the company could face in production.
Written By Karen Chua, IT Management Consultant, Pink Elephant
